Using Sync Streams? Sync Streams support JOINs and nested subqueries, which handle most many-to-many relationships directly without the workarounds described here. See Many-to-Many with Sync Streams for examples.
Postgres users: For Postgres source databases, you can use the
pg_ivm extension to create incrementally maintained materialized views with JOINs that can be referenced directly in Sync Rules. This approach avoids the need to denormalize your schema.Example
As an example, consider a social media application. The app has message boards. Each user can subscribe to boards, make posts, and comment on posts. Posts may also have one or more topics.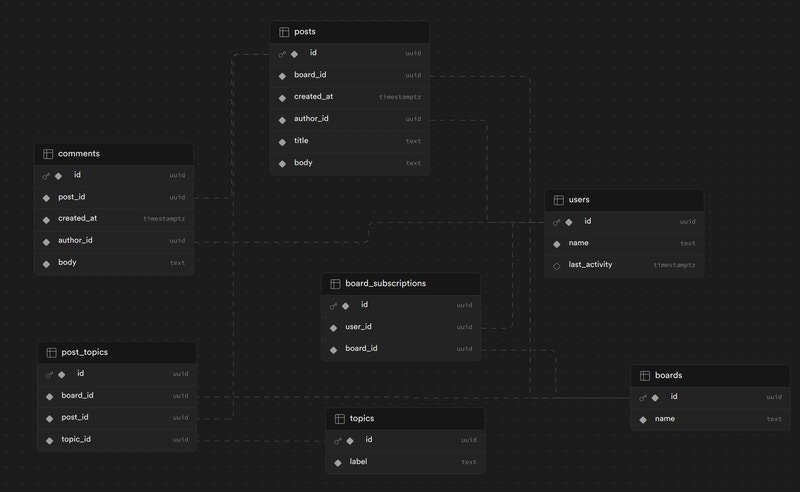
Full schema (for Postgres)
Full schema (for Postgres)
Many-to-many: Bucket parameters
For this app, we generally want to sync all posts in boards that users have subscribed to. To simplify these examples, we assume a user has to be subscribed to a board to post. Boards make a nice grouping of data for Sync Rules: We sync the boards that a user has subscribed to, and the same board data is synced to all users subscribed to that board. The relationship between users and boards is a many-to-many, specified via theboard_subscriptions table.
To start with, in our PowerSync Sync Rules, we define a bucket and sync the posts. The parameter query is defined using the board_subscriptions table:
Avoiding Joins in Data Queries: Denormalize Relationships (Comments)
Next, we also want to sync comments for those boards. There is a one-to-many relationship between boards and comments, via theposts table. This means conceptually we can add comments to the same board bucket. With general SQL, the query could be:
board_id from the start, so post_topics is simple in our Sync Rules:
Many-to-many strategy: Sync everything (topics)
Now we need access to sync the topics for all posts synced to the device. There is a many-to-many relationship between posts and topics, and by extension boards to topics. This means there is no simple direct way to partition topics into buckets — the same topics be used on any number of boards. If the topics table is limited in size (say 1,000 or less), the simplest solution is to just sync all topics in our Sync Rules:Many-to-many strategy: Denormalize data (topics, user names)
If there are many thousands of topics, we may want to avoid syncing everything. One option is to denormalize the data by copying the topic label over topost_topics: (Postgres example)
topics table itself, as everything is included in post_topics. Assuming the topic label never or rarely changes, this could be a good solution.
Next up, we want to sync the relevant user profiles, so we can show it together with comments and posts. For simplicity, we sync profiles for all users subscribed to a board.
One option is to add the author name to each board subscription, similar to what we’ve done for topics: (Postgres example)
Many-to-many strategy: Array of IDs (user profiles)
If we need to sync more than just the name (let’s say we need a last activity date, profile picture and bio text as well), the above approach doesn’t scale as well. Instead, we want to sync theusers table directly. To sync user profiles directly in the bucket for the board, we need a new array.
Adding an array to the schema in Postgres:
Postgres trigger to update subscribed_board_ids
Postgres trigger to update subscribed_board_ids
- Updating the
subscribed_board_idsarray in Postgres becomes slower. - The overhead is even more pronounced on PowerSync, since PowerSync maintains a separate copy of the data in each bucket.