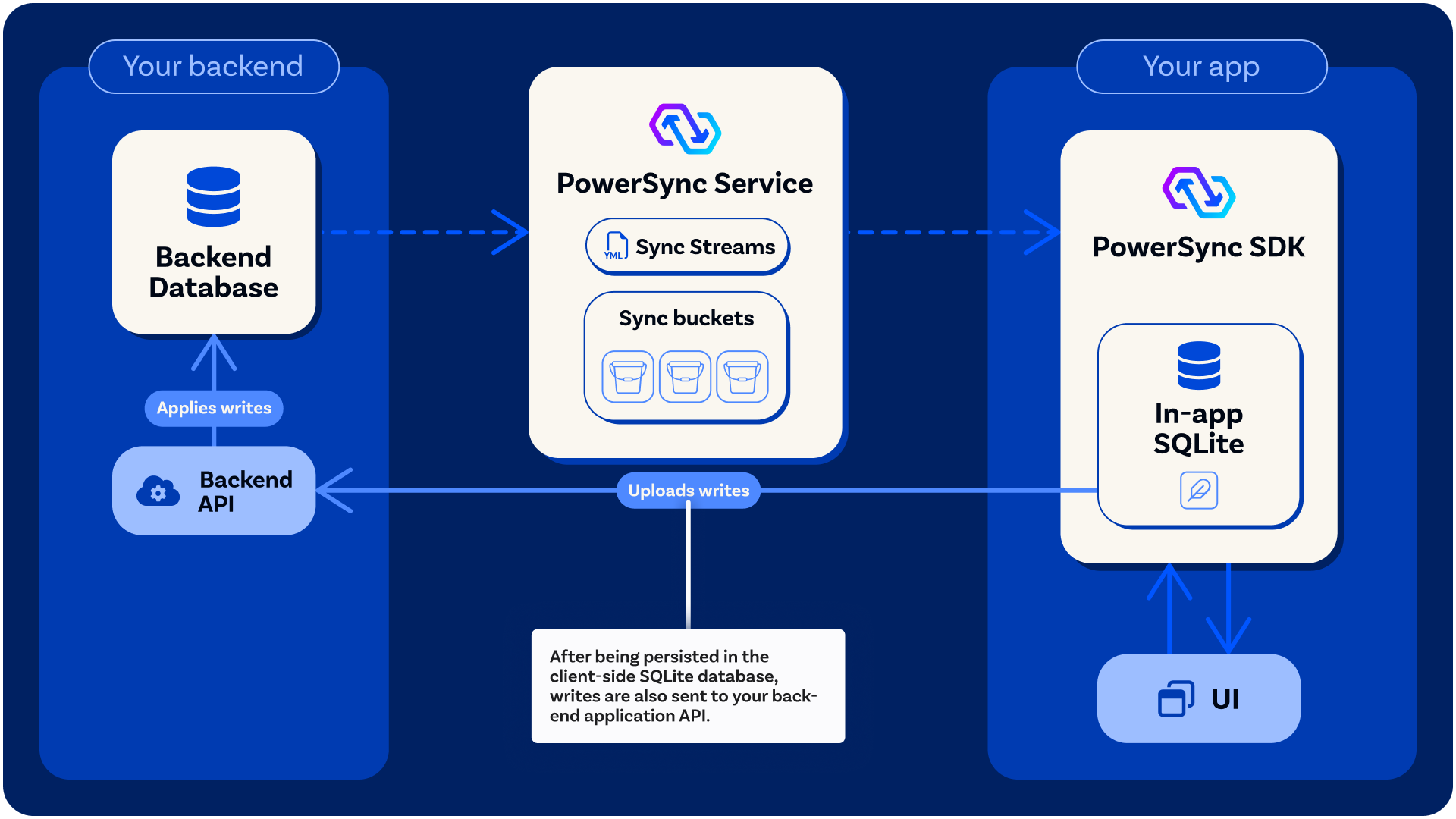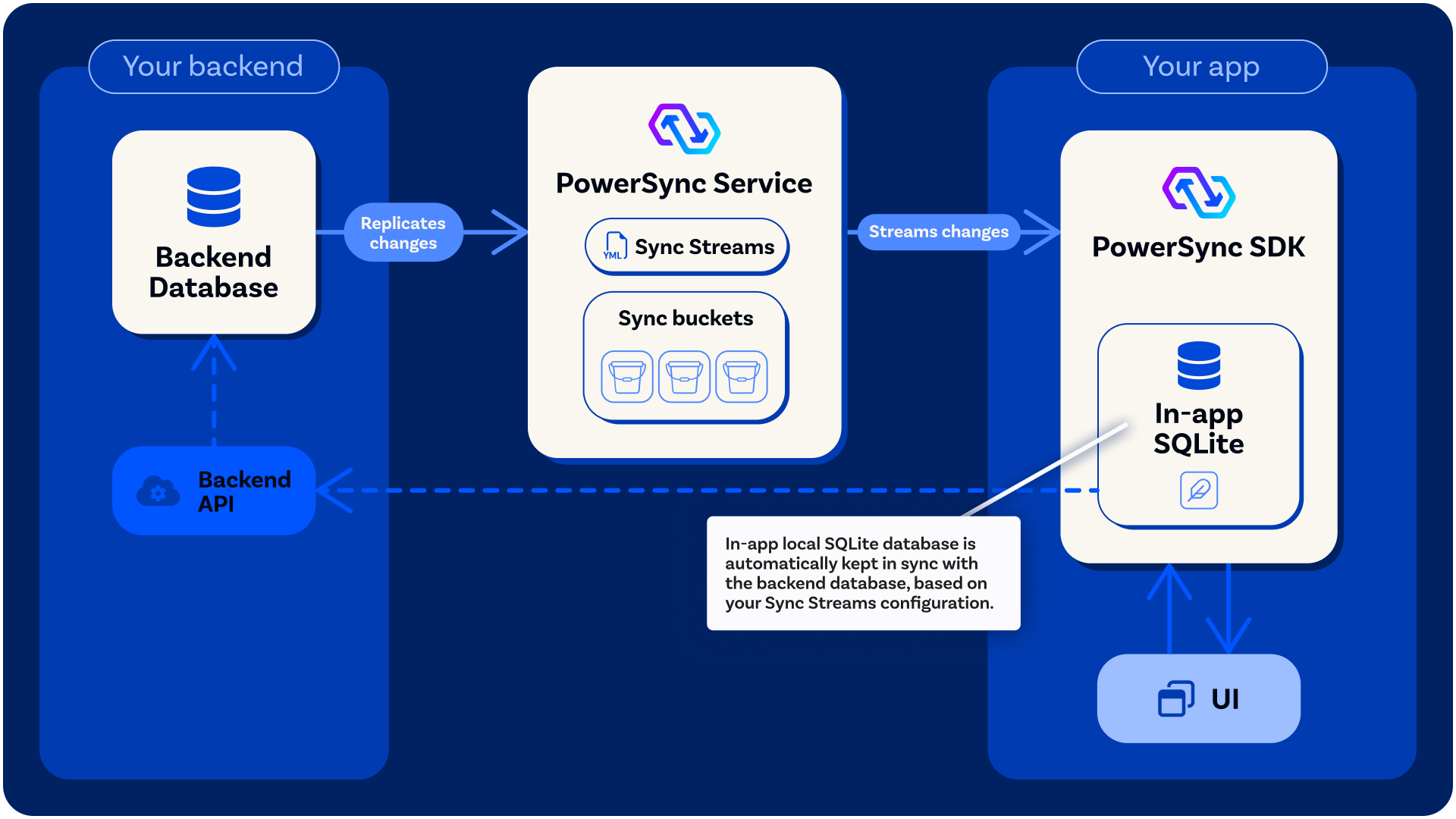
Reading Data (SQLite)
App clients always read data from the client-side SQLite database, regardless of whether the user is online or offline. When the user is online and the app is connected to the PowerSync Service, changes on the source database reflect in real-time in the SQLite database. The app UI can also use Live Queries / Watch Queries for real-time reactivity.Client-Side Schema and SQLite Database Structure
When you implement the PowerSync Client SDK in your application, you need to define a client-side schema with tables, columns and indexes that correspond to your Sync Streams. You provide this schema when the PowerSync-managed SQLite database is instantiated. The tables defined in your client-side schema are usable in SQL queries as if they were actual SQLite tables, while in reality they are created as SQLite views based on the schemaless JSON data being synced (see PowerSync Protocol). The PowerSync Client SDK automatically maintains the following tables in the SQLite database:| Table | Description |
|---|---|
ps_data__<table> | This contains the data for each “table”, in JSON format. Since JSON is being used, this table’s schema does not change when columns are added, removed or changed in the Sync Streams/Rules and client-side schema. |
ps_data_local__<table> | Same as the previous point, but for local-only tables. |
<table> (VIEW) | These are views on the above ps_data tables, with each defined column in the client-side schema extracted from the JSON. For example, a description text column would be CAST(data ->> '$.description' as TEXT). |
ps_untyped | Any synced table that is not defined in the client-side schema is placed here. If the table is added to the schema at a later point, the data is then migrated to ps_data__<table>. |
ps_oplog | This is the operation history data as received from the PowerSync Service, grouped per bucket. |
ps_crud | The client-side upload queue (see Writing Data below) |
ps_buckets | A small amount of metadata for each bucket. |
ps_migrations | Table keeping track of Client SDK schema migrations. |
ps_data__<table> and ps_oplog.
The copy of the row in ps_oplog may be newer than the one in ps_data__<table>. This is because of the checkpoint system in PowerSync that gives the system its consistency properties. When a full checkpoint has been downloaded, data is copied over from ps_oplog to the individual ps_data__<table> tables.
It is possible for different buckets to include overlapping data (for example, if multiple buckets contain data from the same table). If rows with the same table and ID have been synced via multiple buckets, it may be present multiple times in ps_oplog, but only one will be preserved in the ps_data__<table> table (the one with the highest op_id).
Raw Tables Instead of JSON-Backed SQLite Views: If you run into limitations with the above JSON-based SQLite view system, check out the Raw Tables feature which allows you to define and manage raw SQLite tables to work around some of the limitations of PowerSync’s default JSON-backed SQLite views system.
Writing Data (via SQLite Database and Upload Queue)
Any mutations on the SQLite database, namely updates, deletes and inserts, are immediately reflected in the SQLite database, and also automatically placed into an upload queue by the Client SDK. The upload queue is a blocking FIFO queue. The upload queue is automatically managed by the PowerSync Client SDK. The Client SDK processes the upload queue by invoking anuploadData() function that you define when you integrate the Client SDK. Your uploadData() function implementation should call your backend application API to persist the mutations to the backend source database.
PowerSync is designed this way so that you can apply your own backend business logic, validations and authorization to any mutations going to your source database.
The PowerSync Client SDK automatically takes care of network failures and retries. If processing mutations in the upload queue fails (e.g. because the user is offline), it is automatically retried. For a detailed breakdown of when uploadData() is called, including throttling, retry behavior, and error handling, see When uploadData() is Called.