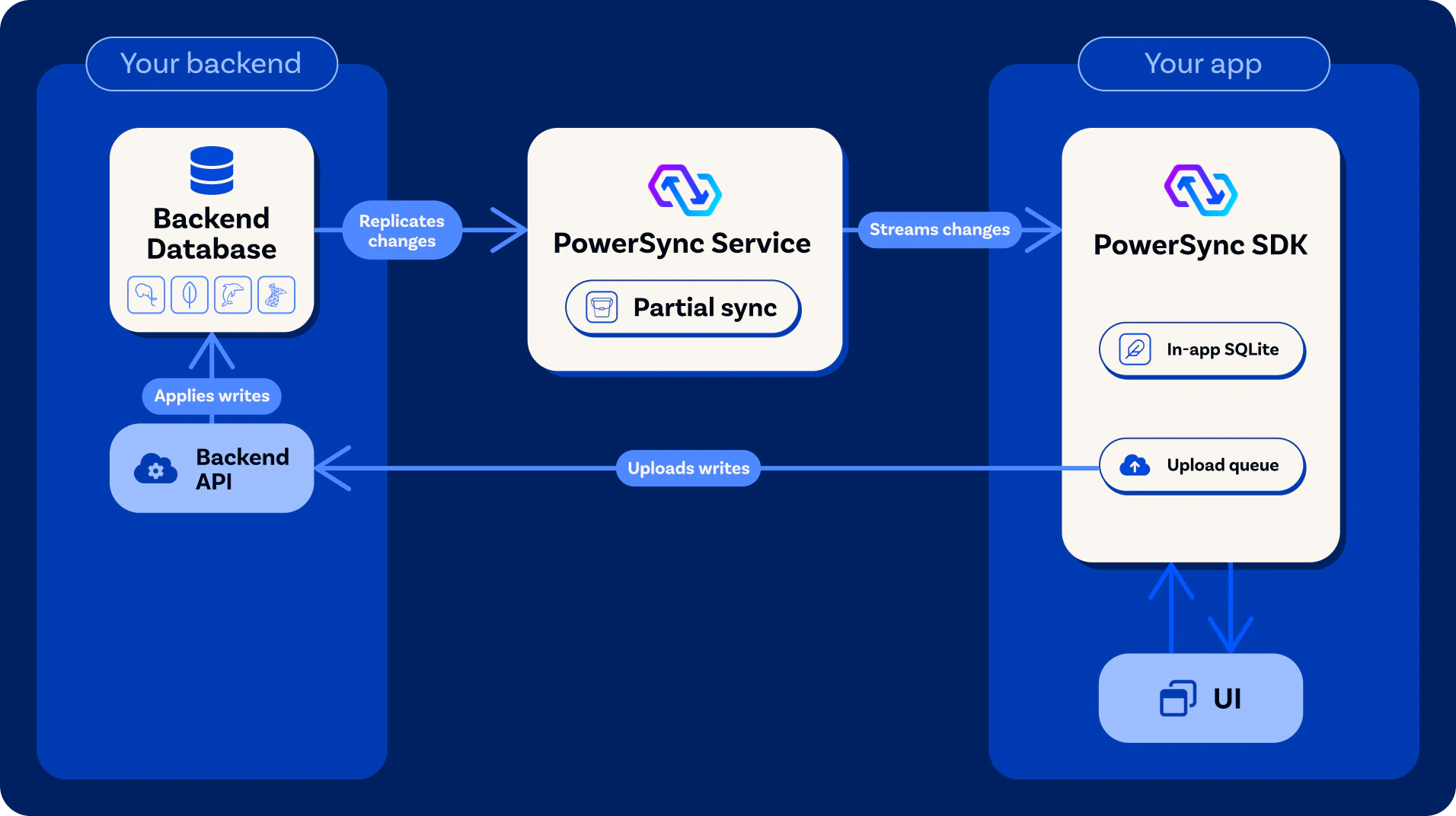
 The [PowerSync Service](/architecture/powersync-service) and client SDK operate in unison to keep client-side SQLite databases in sync with a backend database. Learn about their architecture:
The [PowerSync Service](/architecture/powersync-service) and client SDK operate in unison to keep client-side SQLite databases in sync with a backend database. Learn about their architecture:
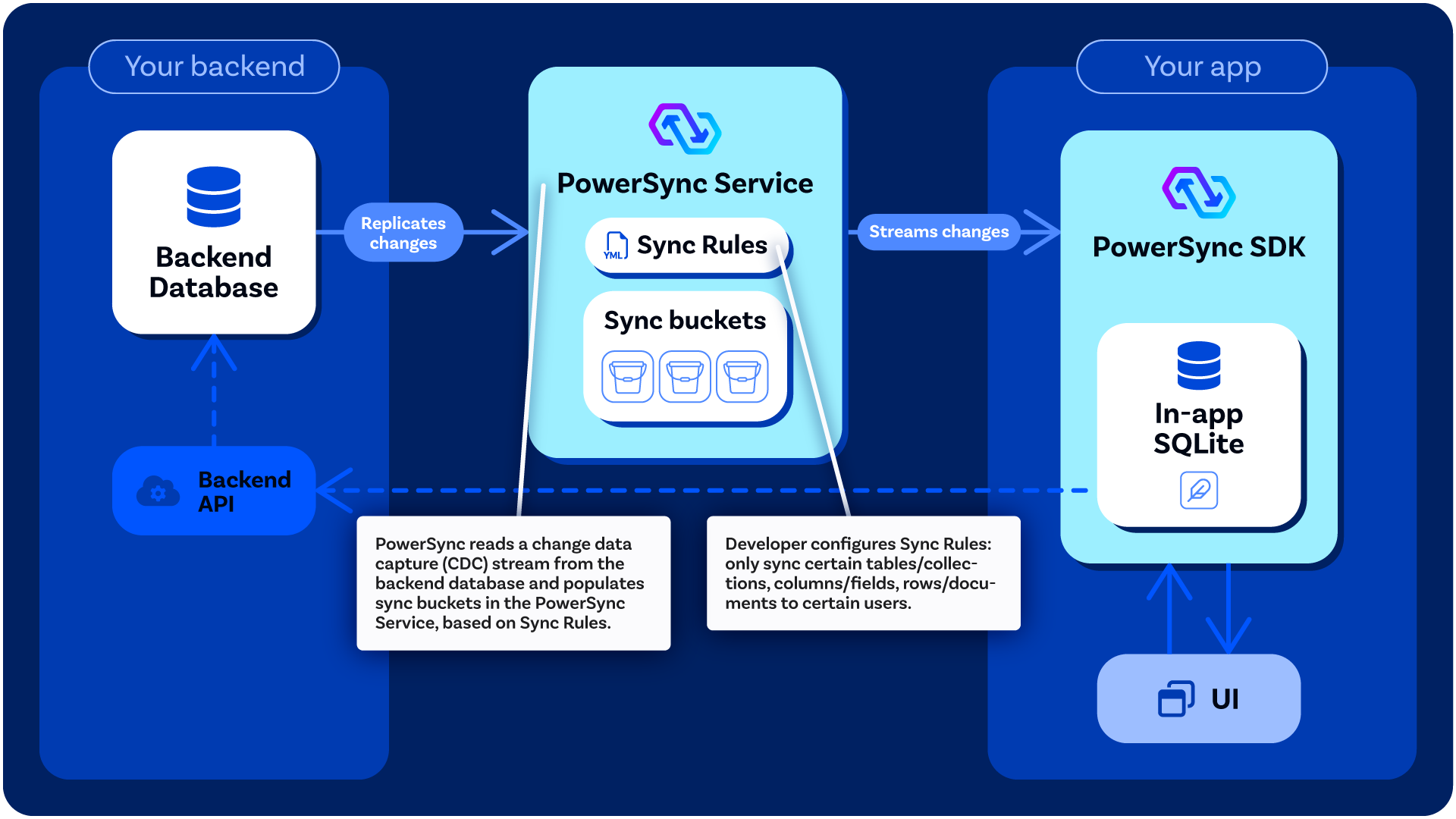 The local SQLite database embedded in the PowerSync SDK is automatically kept in sync with the backend database, based on the [Sync Rules](/usage/sync-rules) configured by the developer:
The local SQLite database embedded in the PowerSync SDK is automatically kept in sync with the backend database, based on the [Sync Rules](/usage/sync-rules) configured by the developer:
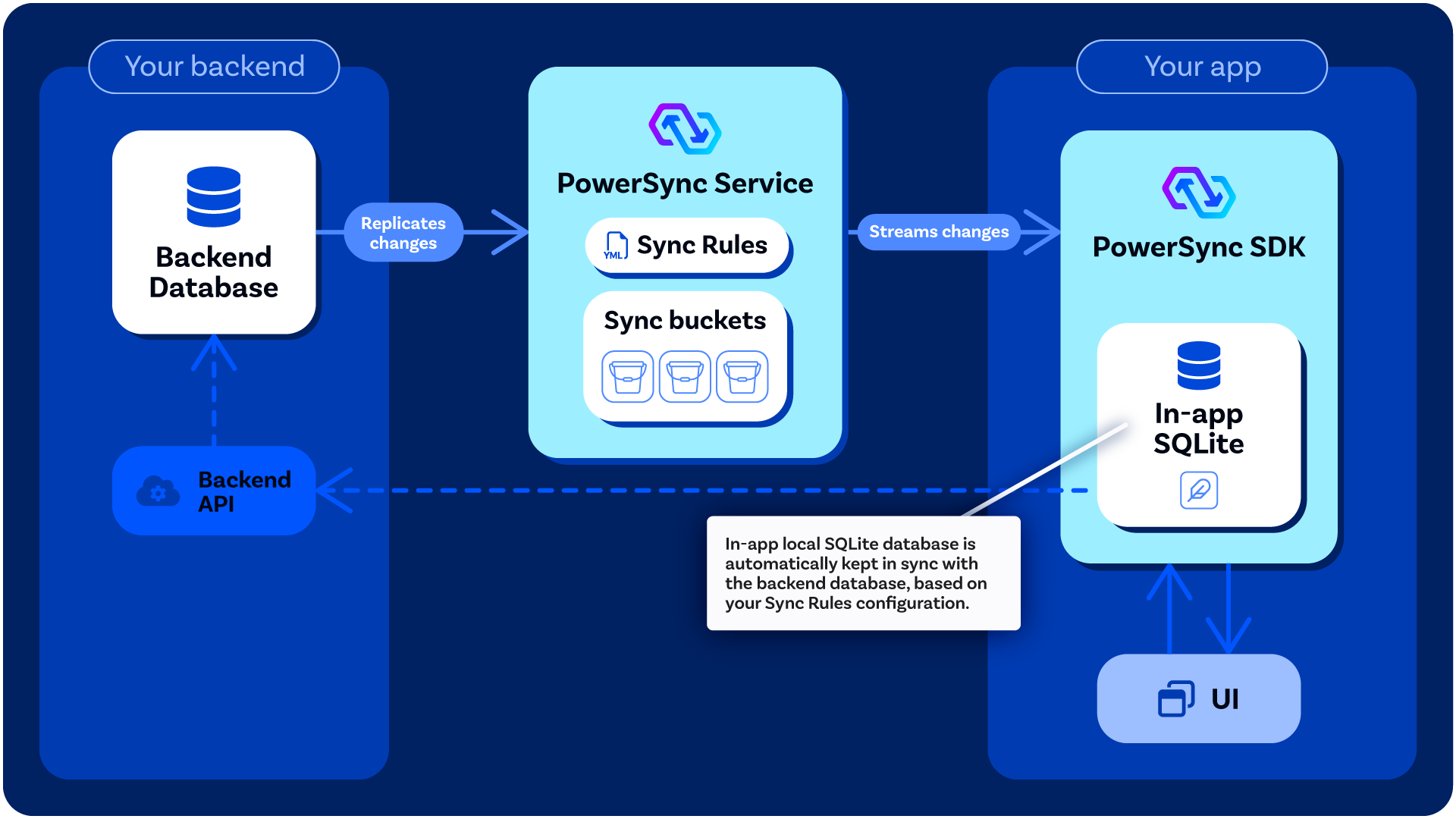 #### Writing Data
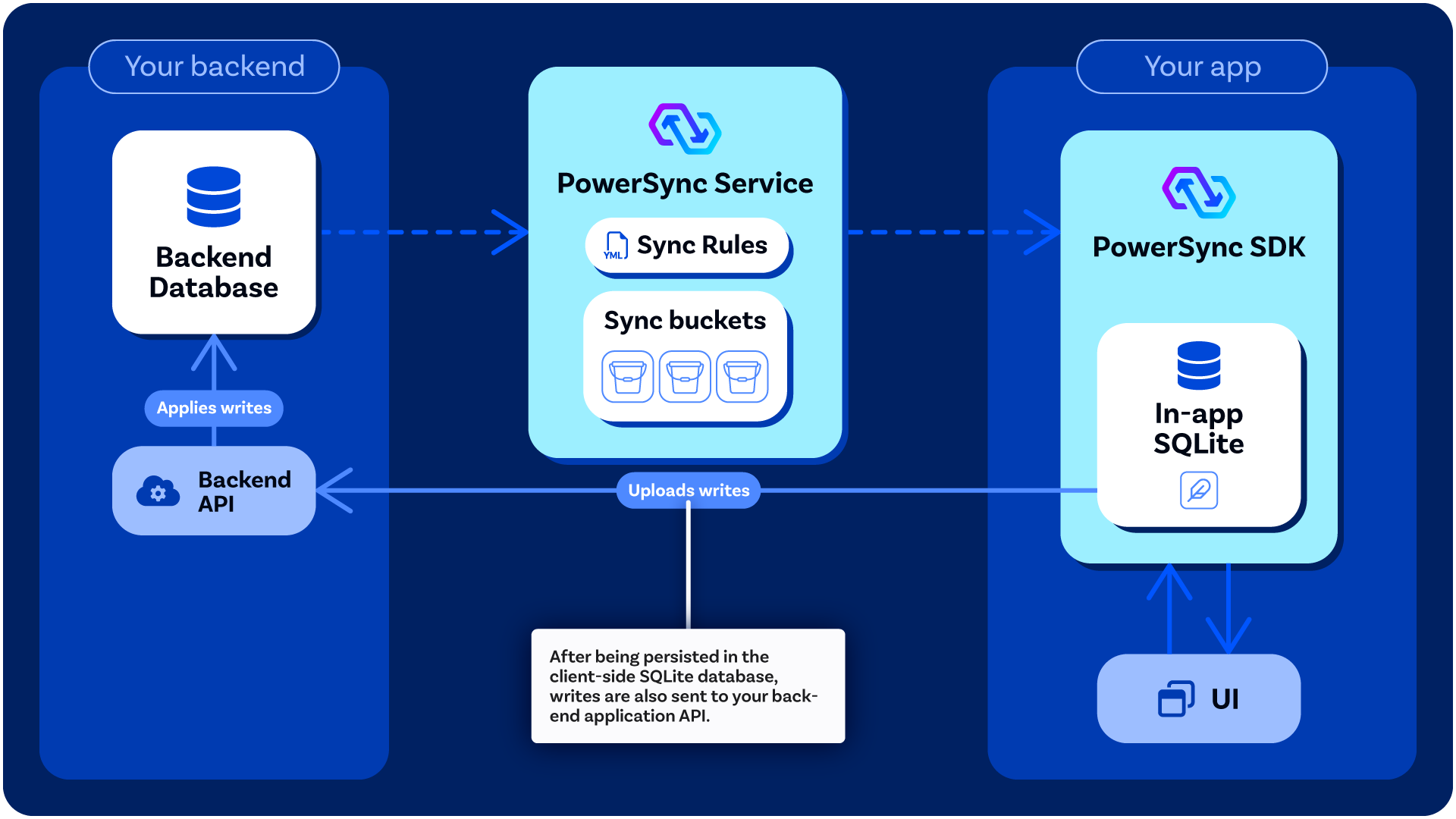
Client-side data modifications, namely updates, deletes and inserts, are persisted in the embedded SQLite database as well as stored in an upload queue. The upload queue is a blocking [FIFO](https://en.wikipedia.org/wiki/FIFO_%28computing_and_electronics%29) queue that gets processed when network connectivity is available.
Each entry in the queue is processed by writing the entry to your existing backend application API, using a function [defined by you](/installation/client-side-setup/integrating-with-your-backend) (the developer). This is to ensure that existing backend business logic is honored when uploading data changes. For more information, see the section on [integrating with your backend](/installation/client-side-setup/integrating-with-your-backend).
#### Writing Data
Client-side data modifications, namely updates, deletes and inserts, are persisted in the embedded SQLite database as well as stored in an upload queue. The upload queue is a blocking [FIFO](https://en.wikipedia.org/wiki/FIFO_%28computing_and_electronics%29) queue that gets processed when network connectivity is available.
Each entry in the queue is processed by writing the entry to your existing backend application API, using a function [defined by you](/installation/client-side-setup/integrating-with-your-backend) (the developer). This is to ensure that existing backend business logic is honored when uploading data changes. For more information, see the section on [integrating with your backend](/installation/client-side-setup/integrating-with-your-backend).
 ### Schema
On the client, the application [defines a schema](/installation/client-side-setup/define-your-schema) with tables, columns and indexes.
These are then usable as if they were actual SQLite tables, while in reality these are created as SQLite views.
The client SDK maintains the following tables:
1. `ps_data__
### Schema
On the client, the application [defines a schema](/installation/client-side-setup/define-your-schema) with tables, columns and indexes.
These are then usable as if they were actual SQLite tables, while in reality these are created as SQLite views.
The client SDK maintains the following tables:
1. `ps_data__